Tackling the Thundering Herd Problem and Designing Idempotent API Endpoints for Payments at Stripe with Rate Limiting


Introduction
APIs are crucial in maintaining the connection between the client and server and are essential for every business to ensure connectivity.
However, when the user base is huge, it comes with some problems like frequent retries of connections by a large user base simultaneously. If it's a payment API, then we have a problem with payments occurring more than once, and the rate at which clients interact can be higher, leading to server failures.
Idempotent APIs
The idempotent property of operations or API requests ensures that repeating the operation multiple times produces the same result as executing it once.
Suppose, let's take an example. Let's say that Person A has made an API call to the backend, and due to some issue, the API call fails. In that situation, we can do three things:
Ignore the error and move forward.
Pass the observed error to the user and let the user decide what to do.
Retry resolving the error on our own.
We choose the third option as it leads to a better user experience, and that's what we are known for. We provide more control in our hands, but this also involves examining various scenarios. Depending on where the failure happens, we can determine whether to retry the API call or not, considering the following three possible scenarios where the error might occur
The client request didn't reach the server, resulting in no processing of the request. Therefore, we can easily retry the API call.

The client sent the request, but if the server experiences a network termination or an invalid connection while processing the request, we can't retry the API call. This is because we don't know at which stage the computation failed.

The client sent the request, the server received and performed the computation, but when the client attempts to receive the response, the request fails. In this case, we cannot retry, as the client is unaware that the server has already completed the computation.

Idempotency Keys
Now, let's consider a scenario where person A is transferring an amount of $10,000 to B. First, he will go to an authorized URL and initiate the transfer. Now, suppose the API call fails at conditions two and three. If we retry, we won't know whether the amount has been deducted or not. As we retry, the amount may deduct again. Therefore, we need to determine if the server has processed the request before. We need to build a system robust enough to decide whether to retry the API or not, depending on the situation.
In simple terms, the system should be idempotent, also known as the Exactly Once Semantic. When the server sees the request for the first time, it should process it. If it sees the request again after some time, it should either throw an error or ignore it, depending on the use case.
One approach to achieving this is to send the request in a URL and, to identify whether it is the same request, store the payload as a single website or webpage that can handle or perform multiple types of requests. For fast lookup, pass the payload into a hash function and store the generated hash value.
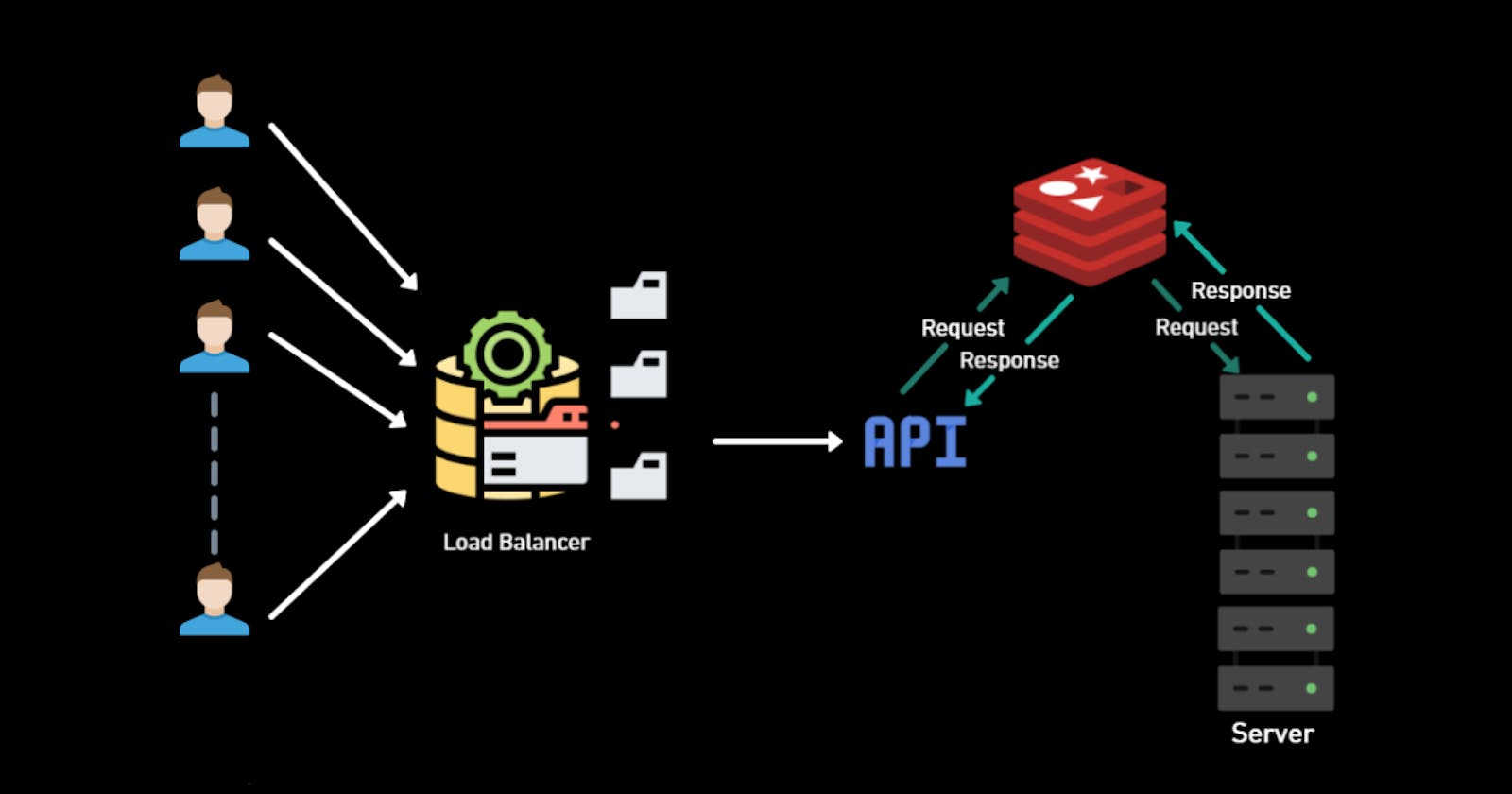
However, to simplify things, we can store the requests in terms of Idempotency keys. These idempotency keys are randomly generated IDs by the server based on different parameters and the purpose of the user accessing the API, such as the amount and the service accessed via the webpage. These idempotency keys are stored in a high-throughput database like Redis.
Now, when the client sends the request, before reaching the server, the request is converted into idempotent keys and transferred to the server. When the server sees the idempotent key, it checks whether it is present in the database. If it is present, the server ignores or rejects the request; if it is not present, it will process the request.
Platforms like Stripe expect us to include Idempotency Keys in the request header, as a parameter as Idempotency_key .

The code below is for Redis and Stripe integration with the functions provided in the diagram above
import { v4 as uuidv4 } from "uuid";
import * as redis from "redis";
// Initialize a Redis client
const redisClient = redis.createClient();
// Function to generate Idempotency keys
function generateIdempotencyKey(parameters: any): string {
// Generate a unique ID based on different parameters
const idempotencyKey = uuidv4();
redisClient.set(idempotencyKey, JSON.stringify(parameters), "EX", 3600);
return idempotencyKey;
}
// Function to check if Idempotency key exists in Redis
function isIdempotencyKeyExists(idempotencyKey: string): Promise<boolean> {
return new Promise((resolve, reject) => {
redisClient.exists(idempotencyKey, (error: any, reply: any) => {
if (error) {
reject(error);
} else {
resolve(Boolean(reply));
}
});
});
}
async function handlePaymentRequest(clientRequest: any) {
// Convert the client request into an idempotency key
const idempotencyKey = generateIdempotencyKey({
amount: clientRequest.amount,
service: clientRequest.service,
});
const keyExists = await isIdempotencyKeyExists(idempotencyKey);
if (keyExists) {
console.log(
`Request with Idempotency Key ${idempotencyKey} already processed. Ignoring.`
);
} else {
const requestHeaders = {
"Idempotency-Key": idempotencyKey,
// Add other headers as needed
};
sendPaymentRequestToStripe(clientRequest, requestHeaders);
}
}
function sendPaymentRequestToStripe(clientRequest: any, headers: any) {
// Replace the below line with your actual Stripe API request logic
console.log(
`Sending payment request to Stripe with Idempotency Key: ${headers["Idempotency-Key"]}`
);
}
const paymentRequestExample = {
amount: 10000,
service: "payment",
};
handlePaymentRequest(paymentRequestExample);
Handling Thundering Herd Problem
let us say a Client A makes a API call(Assuming the API is idempotent) to the backend and for some issue the API call fall then we do retry it works for the fewer clients then if there are millions of requests then everyone one will try until the API is completed it will bombard the server this is called the thunder Herd Problem
Let us consider a naive way to solve the problem. We can run a for loop from 1 to the limit of maximum retries and call the API again, as shown in the code below
const maxRetries: number = 3;
for (let i = 0; i <= maxRetries; i++) {
apiCall();
}
This approach works fine when there are fewer clients, but if you have millions of clients sending requests to the server simultaneously, let's assume the server is a bit overwhelmed, resulting in API call failures for many clients. Now, most clients will attempt to make API calls to the server again, and the server, burdened with the extra load of new API calls, doesn't get sufficient time to recover, leading to a prolonged outage.
To address this issue, let's add backoff, specifically exponential backoff, to the server. Instead of immediately retrying, we introduce a buffer in between, exponentially spaced, allowing the server some time to recover.
While this may seem like a solution, when a maximum percentage of users' requests coincides at the same time, even after applying exponential backoff, the clients' requests nearly coincide, which is not very efficient.
To solve this problem, instead of retrying immediately after exponential backoff, we add random jitter. This ensures fewer coincidences over retries, spacing out the repetitions or retries made on the server, giving it enough time to recover and reducing the number of requests coinciding as retries
The code of the above explanation is as follows
import axios, { AxiosResponse, AxiosError } from "axios";
async function retryApiRequest<T>(
apiCall: () => Promise<AxiosResponse<T>>,
maxRetries: number = 3,
baseDelay: number = 1000
): Promise<T> {
let retries: number = 0;
const delay = (ms: number): Promise<void> => {
return new Promise((resolve) => setTimeout(resolve, ms));
};
const exponentialBackoff = async (): Promise<void> => {
const delayTime: number = baseDelay * Math.pow(2, retries);
await delay(delayTime);
};
const addJitter = async (ms: any): Promise<void> => {
// Random jitter between -0.1 and 0.1
const randomJitter: number = Math.random() * 0.2 - 0.1;
const jitteredDelay: number = ms + ms * randomJitter;
await delay(jitteredDelay);
};
while (retries < maxRetries) {
try {
const response: AxiosResponse<T> = await apiCall();
return response.data;
} catch (error) {
const axiosError: AxiosError = error as AxiosError;
if (!axiosError.response) {
retries++;
await addJitter(await exponentialBackoff());
} else {
throw error;
}
}
}
throw new Error(`Max retries reached (${maxRetries})`);
}
// Example usage
const apiUrl: string = "https://api.example.com/data";
const apiCall = async (): Promise<AxiosResponse<any>> => {
return axios.get(apiUrl);
};
retryApiRequest(apiCall)
.then((data: any) => {
console.log("API call successful:", data);
})
.catch((error: Error) => {
console.error("API call failed:", error.message);
});
Rate Limiter
This optimizes the user experience when retrying the API and using the server. Taking it a step further, we can also implement a rate limiter for our website.
Through the rate limiter, we can restrict only a particular number of API calls happening to the server, making the remaining ones display a loading UI. If the server cannot handle the requests, we can show another UI on the website, requesting users to visit after some time. To implement this, we can maintain a database for both the server and the rate limiter. The server can track the number of requests in progress, and the rate limiter can determine whether there is space to accept additional requests or not.

Final Thoughts
Through the methods stated and explained above, we can ensure a resilient and efficient system for handling a multiple number of client requests, enhancing both reliability and user experience.
If you found this blog insightful, continue exploring similar content on my profile. I've also provided valuable resources that can help you learn more about optimizing the request-response cycle by designing idempotent API endpoints and implementing rate limiting.
Resources
Explore the official Stripe blog on designing robust and predictable APIs with idempotency at Stripe Idempotency Blog.
Learn more about the Thundering Herd Problem on the Wikipedia page: Thundering Herd Problem Wikipedia.
Deep into the University of Texas at Austin's blog on Adaptive Backoff Algorithms for Multiple Access: Adaptive Backoff Algorithms Blog.